

医疗大模型临床实战能力综合评测体系
以临床实战为核心,涵盖准确性与安全性的全场景医疗 AI 评测基准
0+
黄金测评数据
0
核心应用场景
0+
评测维度
0
大专项子榜单
为什么需要
DoctorBench
?
"应试型"评测的局限
传统多选题、填空题等评测方式难以反映模型在真实诊疗场景中的综合表现,无法评估其临床推理与决策能力。
"学术型"NLP任务的隔阂
医学 NER、关系抽取等任务与临床实际应用存在较大差距,模型在任务上的高分未必转化为临床可用性。
语言与场景的鸿沟
中文医疗场景、本土诊疗规范与海外评测基准存在显著差异,需要面向中国临床实践的专属评测体系。

多维度评测架构
三大评测专项全面涵盖大语言模型、多模态大模型与临床任务(智能体)在医疗场景的能力评估
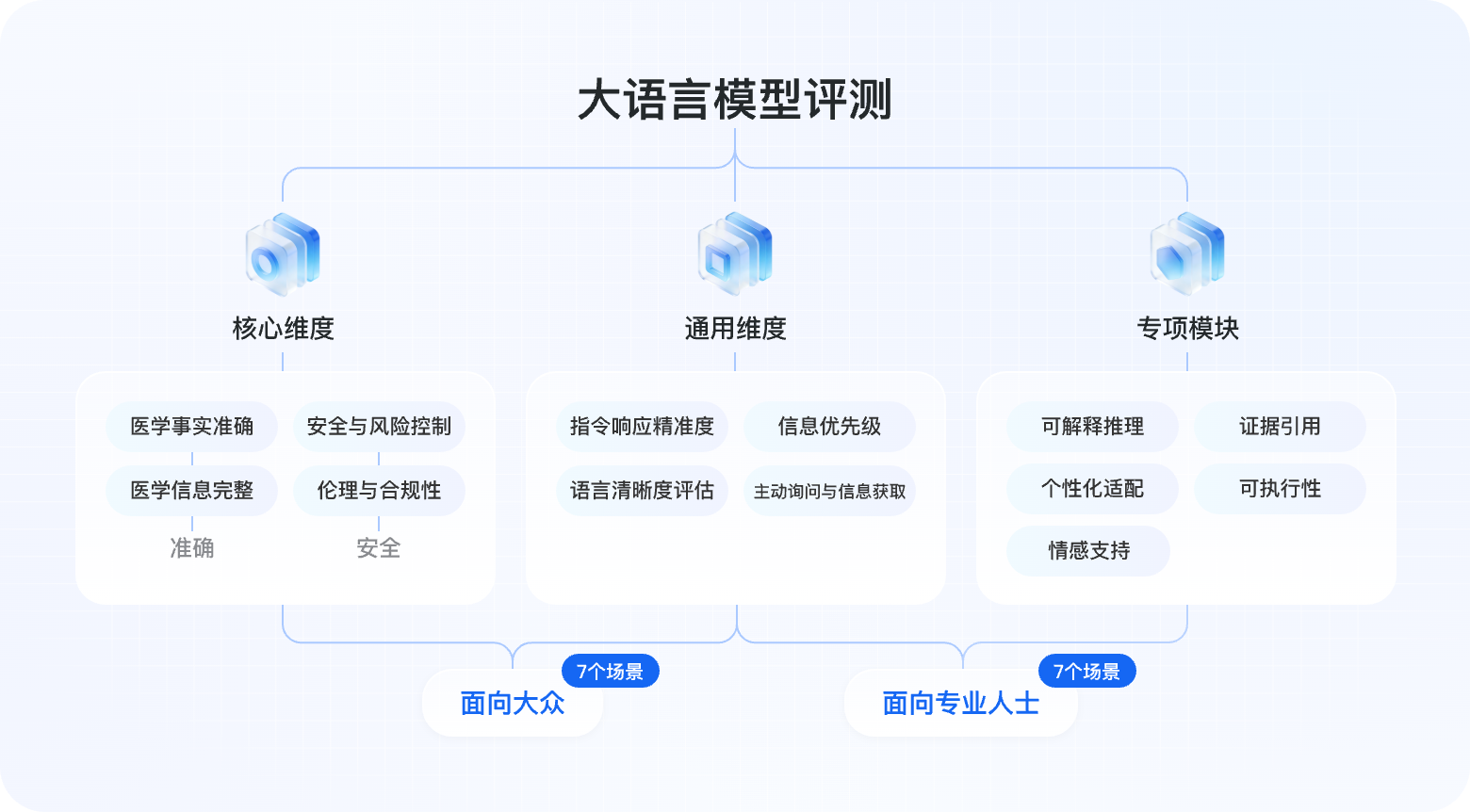
大语言模型评测
基于 14 个临床场景,涵盖 10+ 评测维度(核心/通用/专项),8,890 条高质量评测数据,全面评估大语言模型在中文医疗场景的实战表现。
8890条
评测数据
14类
应用场景
10+
评测维度
评测维度体系
涵盖三大类别、十余项维度,全面系统地评估模型医疗能力
医学事实准确
评估基础的医学事实、诊断依据、病理生理机制、药物作用等信息的科学准确性与临床可靠性。要求与权威医学文献和临床指南一致。
医学信息完整
评估回答是否覆盖问题所涉关键临床点,是否遗漏重要医学要素(如病史、不良反应、鉴别诊断等),以及信息结构的完整性。
安全与风险控制
评估模型是否识别并提示医疗风险,是否避免给出可能危害患者安全的建议,是否在必要时明确建议就医寻求专业诊断。
伦理与合规性
评估回答是否符合医学伦理规范,是否尊重患者隐私与知情同意,是否避免过度承诺疗效或替代专业医疗建议。
高信噪比黄金评测数据

覆盖症状查询、健康科普、用药指导、报告解读等日常健康场景,帮助评估模型服务普通用户的能力。
7个场景5400条数据

涵盖临床决策、医学知识查询、科研辅助、文书生成等专业场景,评估模型支持医疗工作者的能力。
7个场景3490条数据
14大核心应用场景
症状查询与分析
1200条数据
用户描述身体不适症状,模型需帮助分析可能原因、严重程度及建议的应对措施,同时强调不能替代专业诊断。
疾病与健康知识科普
980条数据
用户询问疾病成因、预防、日常保健等科普性问题,模型需提供准确、易懂的医学知识,并区分科普与诊疗建议。
诊疗方案与用药指导
850条数据
用户询问已确诊疾病的治疗方案、药物用法或康复建议,模型需基于循证医学提供参考信息,并强调遵医嘱的重要性。
检查/检验报告解读
720条数据
用户提供化验单、影像报告等,模型需协助解读指标含义及可能提示,同时明确不能替代临床诊断。
日常健康与慢病管理
680条数据
用户询问慢性病(如糖尿病、高血压)的日常管理、监测、生活方式调整等问题,模型提供科学、可操作的建议。
医疗资源与政策导航
450条数据
用户询问就医流程、医保政策、医院科室选择、挂号方式等,模型提供准确的流程与政策信息。
心理健康与情感支持
520条数据
用户倾诉情绪困扰、焦虑、抑郁等心理问题,模型在提供基础心理慰藉知识的同时,表达同理心并建议必要时寻求专业帮助。
诚邀共创
期待您的模型加入 DoctorBench 评测,共同推动医疗 AI 走向更精准、更安全的未来