

Real-world clinical evaluation framework for medical foundation models
Built around real clinical practice, with full-scenario medical AI benchmarks covering both accuracy and safety.
0+
Gold-standard cases
0
Core scenarios
0+
Evaluation dimensions
0
Specialty leaderboards
Why choose
DoctorBench
?
Limits of exam-style benchmarks
Traditional multiple-choice and fill-in-the-blank benchmarks fail to reflect how models perform in real clinical workflows, especially for reasoning and decision-making.
The gap between academic NLP and clinics
Tasks such as medical NER and relation extraction are still far from day-to-day clinical practice, so high benchmark scores do not always translate into practical usefulness.
Language and scenario gaps
Chinese medical scenarios and local care standards differ substantially from overseas benchmarks, which calls for a dedicated evaluation system rooted in Chinese clinical practice.

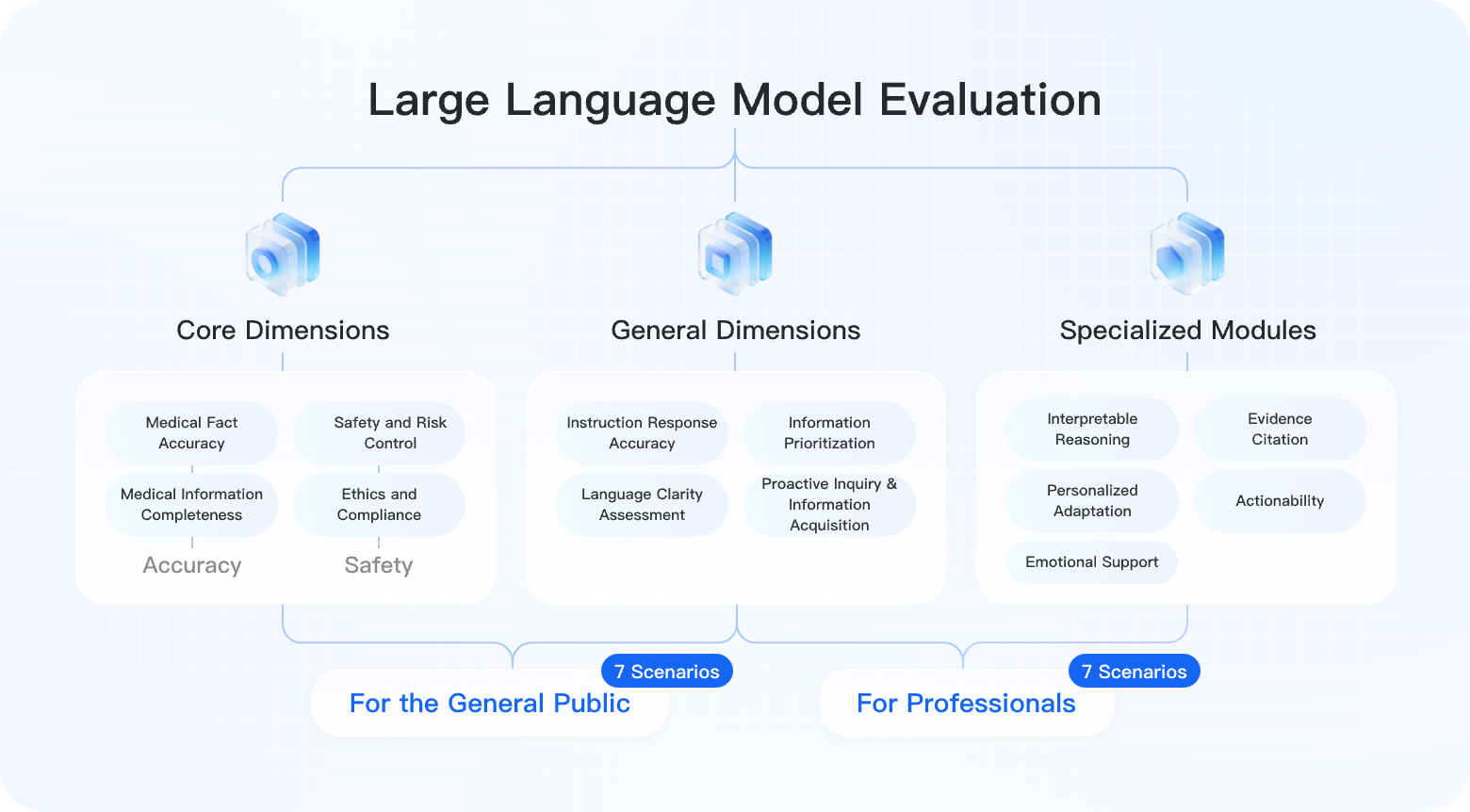
Multi-dimensional evaluation architecture
Three evaluation tracks cover LLMs, multimodal models, and Clinical Tasks (Agent) across real healthcare scenarios.
LLM Evaluation
Built on 14 clinical scenarios, 10+ evaluation dimensions, and 8,890 high-quality samples to assess real-world performance of large language models in Chinese medical settings.
8,890
Samples
14
Scenarios
10+
Dimensions
Evaluation dimensions
Three categories and 10+ dimensions for a systematic view of medical model capability.
Medical factual accuracy
Assesses whether medical facts, diagnostic evidence, mechanisms, and drug knowledge are scientifically accurate and clinically reliable.
Medical information completeness
Checks whether key clinical points are fully covered without omitting important items such as history, adverse reactions, or differential diagnoses.
Safety and risk control
Measures whether the model identifies medical risks, avoids unsafe recommendations, and clearly advises users to seek professional care when needed.
Ethics and compliance
Evaluates whether responses follow medical ethics, respect privacy and informed consent, and avoid overpromising efficacy or replacing professional care.
High-signal gold-standard evaluation data

Covers everyday healthcare scenarios such as symptom triage, health education, medication guidance, and report interpretation for public users.
7 scenarios5,400 samples

Covers professional workflows such as clinical decision support, medical knowledge lookup, research assistance, and document drafting.
7 scenarios3,490 samples
14 core application scenarios
Symptom search and analysis
1,200 samples
The model analyzes possible causes, severity, and next-step advice from user-described symptoms, while clearly stating it does not replace professional diagnosis.
Disease and health education
980 samples
The model answers questions about disease causes, prevention, and daily care with accurate and easy-to-understand medical information.
Treatment and medication guidance
850 samples
The model provides evidence-based reference information for treatment plans, medication usage, and recovery after a confirmed diagnosis.
Lab and imaging report interpretation
720 samples
The model helps interpret test values, imaging findings, and possible implications, while making it clear that it does not replace clinical diagnosis.
Daily health and chronic care management
680 samples
The model supports questions on chronic disease management, monitoring, and lifestyle adjustment with practical and science-based advice.
Healthcare navigation and policy guidance
450 samples
The model explains care pathways, insurance policies, department selection, and appointment workflows with accurate guidance.
Mental health and emotional support
520 samples
The model responds to anxiety, depression, and emotional distress with empathy, basic supportive knowledge, and advice to seek professional help when needed.
Build with us
Bring your model to DoctorBench and help move medical AI toward a safer and more precise future.