

醫療大模型臨床實戰能力綜合評測體系
以臨床實戰為核心,涵蓋準確性與安全性的全場景醫療 AI 評測基準
0+
黃金評測資料
0
核心應用場景
0+
評測維度
0
專項子榜單
為什麼需要
DoctorBench
?
"應試型"評測的局限
傳統多選題、填空題等評測方式難以反映模型在真實診療場景中的綜合表現,無法評估其臨床推理與決策能力。
"學術型"NLP 任務的隔閡
醫學 NER、關係抽取等任務與臨床實際應用存在較大差距,模型在任務上的高分未必能轉化為臨床可用性。
語言與場景的鴻溝
中文醫療場景、本土診療規範與海外評測基準存在顯著差異,需要面向中國臨床實踐的專屬評測體系。

多維度評測架構
三大評測專項全面涵蓋大語言模型、多模態大模型與臨床任務(智能體)在醫療場景中的能力評估
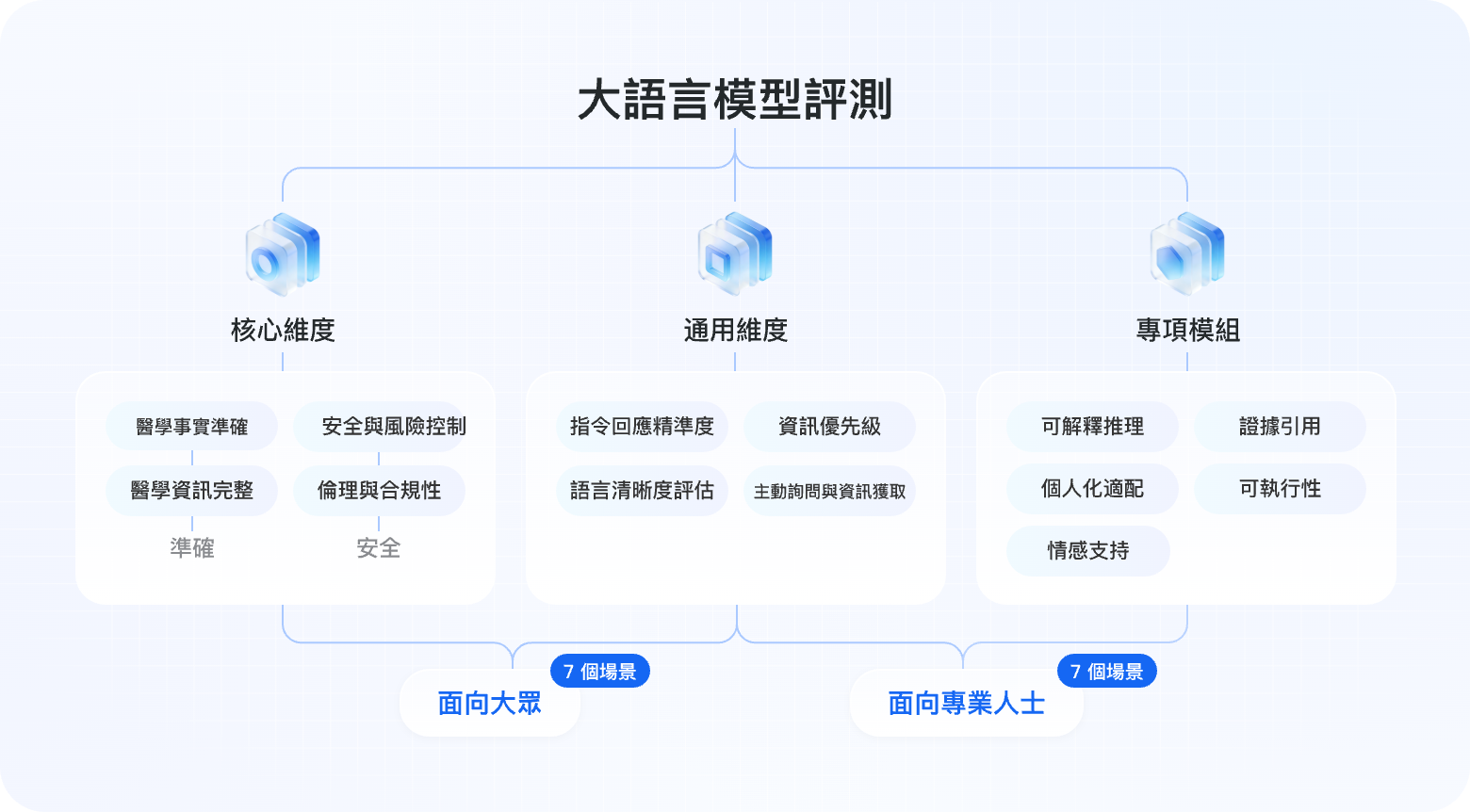
大語言模型評測
基於 14 個臨床場景,涵蓋 10+ 評測維度(核心/通用/專項),8,890 條高品質評測資料,全面評估大語言模型在中文醫療場景的實戰表現。
8890條
評測資料
14類
應用場景
10+
評測維度
評測維度體系
涵蓋三大類別、十餘項維度,全面系統地評估模型醫療能力
醫學事實準確
評估基礎醫學事實、診斷依據、病理生理機制、藥物作用等資訊的科學準確性與臨床可靠性,需與權威醫學文獻及臨床指南一致。
醫學資訊完整
評估回答是否覆蓋問題涉及的關鍵臨床點,是否遺漏重要醫學要素(如病史、不良反應、鑑別診斷等),以及資訊結構是否完整。
安全與風險控制
評估模型是否能識別並提示醫療風險,是否避免給出可能危害患者安全的建議,並在必要時明確建議就醫尋求專業診斷。
倫理與合規性
評估回答是否符合醫學倫理規範,是否尊重患者隱私與知情同意,是否避免過度承諾療效或取代專業醫療建議。
高信噪比黃金評測資料

覆蓋症狀查詢、健康科普、用藥指導、報告解讀等日常健康場景,幫助評估模型服務一般使用者的能力。
7個場景5400條資料

涵蓋臨床決策、醫學知識查詢、科研輔助、文書生成等專業場景,評估模型支援醫療工作者的能力。
7個場景3490條資料
14 大核心應用場景
症狀查詢與分析
1200條資料
使用者描述身體不適症狀時,模型需協助分析可能原因、嚴重程度及應對措施,同時強調不能取代專業診斷。
疾病與健康知識科普
980條資料
使用者詢問疾病成因、預防、日常保健等科普問題時,模型需提供準確、易懂的醫學知識,並區分科普與診療建議。
診療方案與用藥指導
850條資料
使用者詢問已確診疾病的治療方案、藥物用法或康復建議時,模型需基於循證醫學提供參考資訊,並強調遵醫囑的重要性。
檢查/檢驗報告解讀
720條資料
使用者提供化驗單、影像報告等資料時,模型需協助解讀指標含義及可能提示,同時明確不能取代臨床診斷。
日常健康與慢病管理
680條資料
使用者詢問慢性病(如糖尿病、高血壓)的日常管理、監測、生活方式調整等問題時,模型需提供科學、可操作的建議。
醫療資源與政策導航
450條資料
使用者詢問就醫流程、醫保政策、醫院科室選擇、掛號方式等問題時,模型需提供準確的流程與政策資訊。
心理健康與情感支持
520條資料
使用者傾訴情緒困擾、焦慮、憂鬱等心理問題時,模型需在提供基礎心理慰藉知識的同時,展現同理心並建議必要時尋求專業幫助。
誠邀共創
期待您的模型加入 DoctorBench 評測,共同推動醫療 AI 邁向更精準、更安全的未來