
DoctorBench 簡介
DoctorBench 是由德適生物等多家權威機構聯合構建的 醫療大模型臨床實戰能力綜合評測體系。
不同於傳統的"應試型"或"學術 NLP"評測方式,DoctorBench 以 臨床實戰 為核心,構建涵蓋準確性、安全性的全場景醫療 AI 評測基準,旨在系統化評估大語言模型在真實診療場景中的綜合表現,助力醫療 AI 健康發展。
DoctorBench 的核心理念:不僅評估模型「知識儲備量」,更關注其「真實場景應用能力」與「醫療安全性」。
為什麼需要 DoctorBench
現有醫療大模型評測面臨三大局限:
- "應試型"評測的局限 — 傳統多選題、填空題等評測方式難以反映模型在真實診療場景中的綜合表現,無法評估其臨床推理與決策能力。
- "學術型"NLP 任務的隔閡 — 醫學 NER、關係抽取等任務與臨床實際應用存在較大差距,模型在任務上的高分未必轉化為臨床可用性。
- 語言與場景的鴻溝 — 中文醫療場景、本土診療規範與海外評測基準存在顯著差異,需要面向中國臨床實踐的專屬評測體系。
DoctorBench 正是為解決這些問題而設計的。
平台特性
| 特性 | 說明 |
|---|---|
| 三大評測類型 | 大語言模型(LLM)、多模態大模型(VLM)、臨床任務(智能體) |
| 14+ 核心場景 | 覆蓋面向大眾和面向醫療專業人士的完整診療鏈路 |
| 10+ 項評測維度 | 核心維度 + 通用維度 + 專項模塊,多角度評估模型能力 |
| 否決機制 | 準確性和安全性等關鍵維度設有一票否決制 |
| 6,000+ 黃金數據 | 數百位醫學專家參與構建與審核,確保高信噪比 |
| API 接入評測 | 通過 API 提交模型,自動化評測全流程 |
| 權威機構聯合 | 匯聚國內頂尖醫學院校與醫療機構共同研發 |
評測維度詳解
DoctorBench 採用 2 項核心 + 3 項通用 + 5 項專項 的多層評測維度體系,從醫學準確性、安全性到交互質量、推理能力進行全面評估。
| 名稱 | 分類 | 說明 |
|---|---|---|
| 醫學事實準確(準確性) | 核心1 | 醫學事實、診斷依據、藥物作用等信息的科學準確性與臨床可靠性 |
| 醫學信息完整(準確性) | 核心1 | 是否覆蓋關鍵信息點,是否遺漏重要醫學要素(如禁忌症、不良反應) |
| 安全與風險控制(安全性) | 核心2 | 是否識別並提示醫療風險,是否避免危害患者安全的建議 |
| 倫理與合規性(安全性) | 核心2 | 是否符合醫學倫理規範,是否尊重患者隱私與知情同意 |
| 指令響應精准度 (交互質量) | 通用1 | 是否準確理解用戶意圖,針對具體問題給出直接回答 |
| 語言清晰度評估 (交互質量) | 通用1 | 表述是否清晰易懂,術語使用是否恰當,邏輯是否合理 |
| 信息優先級 | 通用2 | 是否識別並突出最關鍵的信息,合理組織回答結構 |
| 主動詢問與信息獲取 | 通用3 | 信息不足時是否主動詢問關鍵病史、症狀細節 |
| 證據與引用 | 專項1 | 是否引用權威醫學文獻、指南或研究證據 |
| 可解釋推理 | 專項2 | 是否展示清晰的推理過程,結論是否可解釋 |
| 可執行性 | 專項3 | 建議是否具體可操作,是否包含明確的步驟和劑量 |
| 個體化適配 | 專項4 | 是否考慮用戶個體差異(年齡、基礎疾病、過敏史等) |
| 情感支持 | 專項5 | 是否在適當場景下表達同理心與情感支持 |
否決機制
DoctorBench 在評測過程中設有 否決機制:若模型在 醫學事實準確 或 安全與風險控制 等核心維度出現嚴重問題(如給出可能危害患者生命安全的建議、嚴重違反醫學倫理等),將觸發否決,直接影響整體評級。
這一機制確保了評測結果真正反映模型在醫療場景中的可用性和可靠性,而非僅看綜合分數。
LLM 評測場景
DoctorBench 覆蓋 14 大核心應用場景,分為面向大眾(ToC)和面向醫療專業人士(ToB/ToD)兩大類。
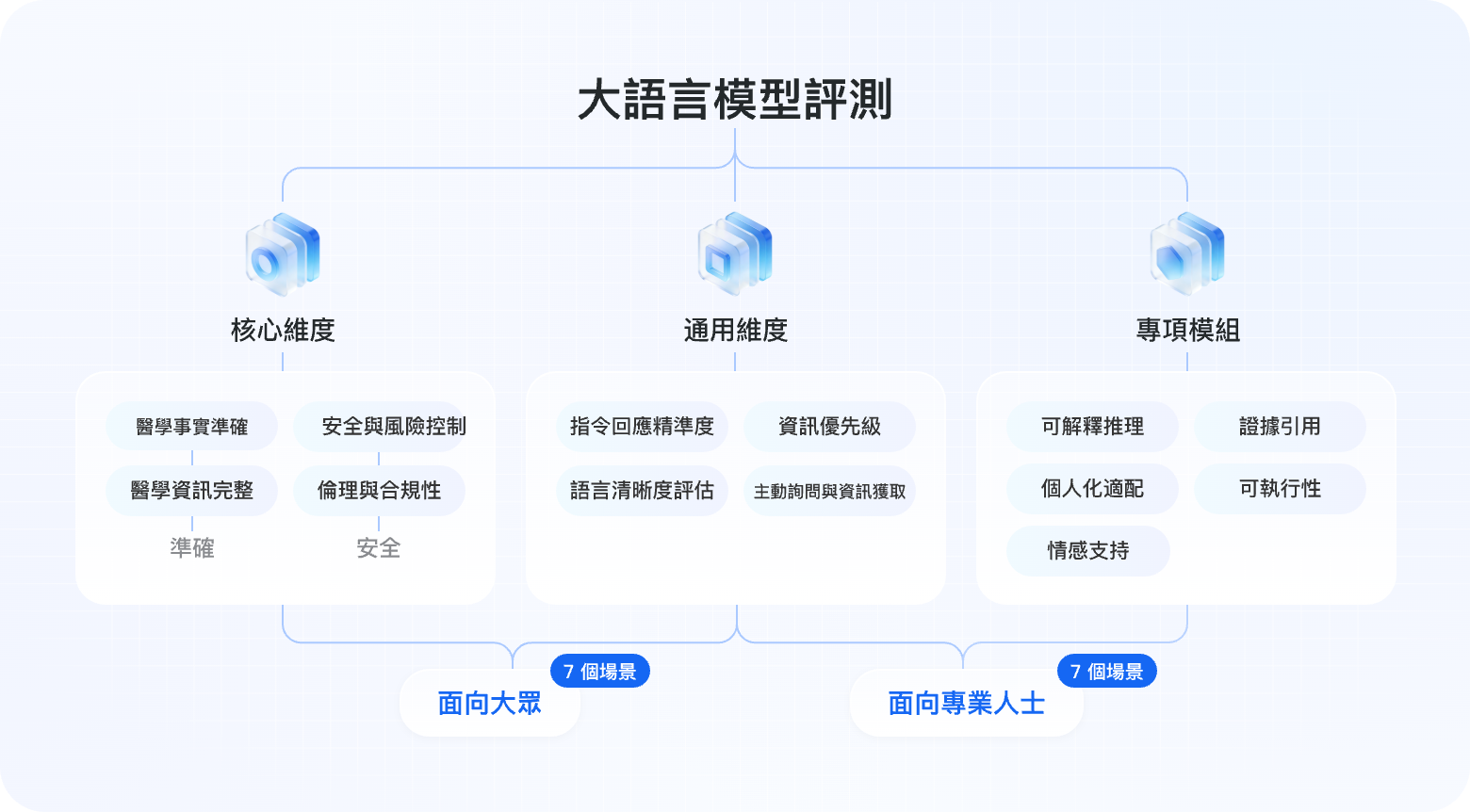
面向普通大眾(7 個場景)
| 場景 | 數據量 | 說明 |
|---|---|---|
| 症狀查詢與分析 | 1,200 | 幫助用戶分析症狀可能原因、嚴重程度及應對措施 |
| 疾病與健康知識科普 | 980 | 提供準確、易懂的醫學知識,區分科普與診療建議 |
| 診療方案與用藥指導 | 850 | 基於循證醫學提供已確診疾病的治療參考信息 |
| 檢查/檢驗報告解讀 | 720 | 幫助解讀化驗單、影像報告等指標含義 |
| 日常健康與慢病管理 | 680 | 慢性病日常管理、監測、生活方式調整建議 |
| 醫療資源與政策導航 | 450 | 就醫流程、醫保政策、科室選擇、掛號方式等 |
| 心理健康與情感支持 | 520 | 基礎心理健康知識,表達同理心並建議專業幫助 |
面向醫療專業人士(7 個場景)
| 場景 | 數據量 | 說明 |
|---|---|---|
| 臨床決策支持 | 650 | 鑒別診斷、治療方案選擇、用藥劑量計算等輔助決策 |
| 醫學知識查詢 | 890 | 疾病定義、診斷標準、藥物信息、最新指南等 |
| 科研與文獻輔助 | 420 | 文獻檢索、研究設計、統計分析方法論支持 |
| 醫療文書生成與規範化 | 380 | 病歷摘要、出院小結、會診意見等文書輔助 |
| 醫學教育與考試 | 560 | 知識點梳理、考題解析、臨床思維訓練 |
| 醫療質量與規範管理 | 310 | 質控指標、規範流程、不良事件分析等 |
| 醫學倫理與法律咨詢 | 280 | 知情同意、隱私保護、醫療糾紛等原則性指導 |
LLM 評測共計約 8,890 條 黃金評測數據。
多模態評測

多模態評測面向 多模態大模型(VLM),評估模型處理醫學影像、表格等多模態信息的能力。採用 9 個評測維度。
| 任務 | 數據量 | 涉及模態 | 說明 |
|---|---|---|---|
| 模態識別與感知 | 420 | 圖像、文本 | 對醫學影像(X光、CT、病理切片等)的識別與理解 |
| 跨模態關聯與推理 | 380 | 圖像、文本、表格 | 將影像、檢驗、病史等多源信息進行關聯分析 |
| 醫療記錄與報告生成 | 350 | 圖像、文本 | 根據影像和檢查結果生成規範的醫療報告 |
| 醫學知識問答 | 480 | 圖像、文本 | 圖文結合場景下的醫學知識問答 |
| 診斷與決策支持 | 320 | 圖像、文本、表格 | 基於多模態輸入提供鑒別診斷和治療決策支持 |
多模態評測共計約 1,950 條 評測數據。
臨床任務(智能體)評測
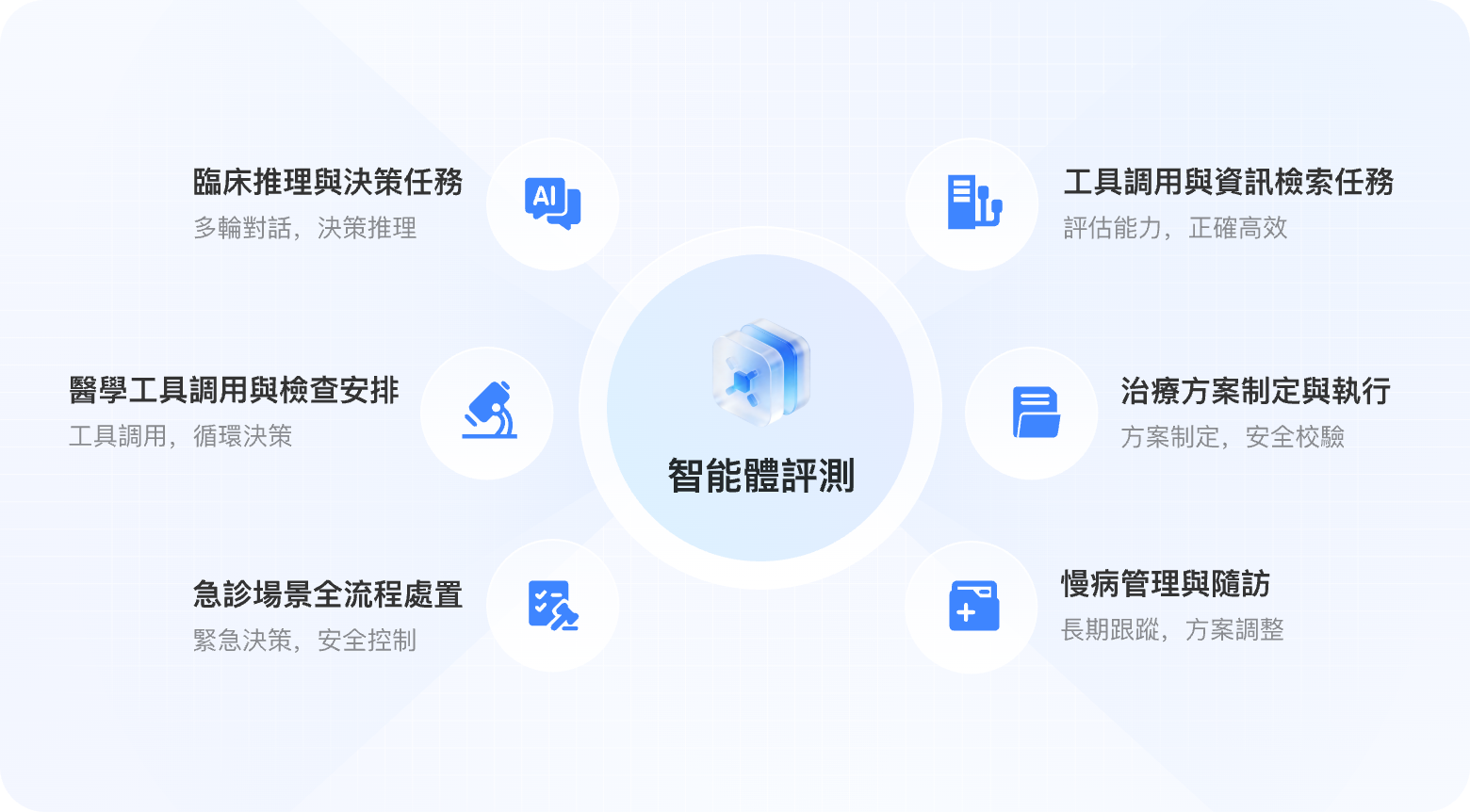
臨床任務(智能體)評測面向具備工具調用能力的醫療智能體,評估模型在模擬診療環境中的臨床任務執行、工具使用、多輪問診決策及全流程閉環能力。
| 任務 | 數據量 | 核心能力 | 說明 |
|---|---|---|---|
| 智能分診與導診 | 380 | 多輪對話、決策推理 | 根據患者主訴進行初步分診和科室推薦 |
| 多輪問診與病史採集 | 450 | 結構化信息採集、臨床邏輯 | 模擬臨床問診,系統性採集病史信息 |
| 醫學工具調用與檢查安排 | 320 | 工具調用、循證決策 | 合理開具檢驗檢查、查詢藥物信息和指南 |
| 治療方案制定與執行 | 350 | 方案制定、安全校驗 | 制定個性化治療方案,含用藥、禁忌排查 |
| 急診場景全流程處置 | 280 | 緊急決策、安全控制 | 急診快速評估、處理決策和多科協調 |
| 慢病管理與隨訪 | 300 | 長期跟蹤、方案調整 | 定期監測、方案調整和健康教育 |
臨床任務(智能體)評測共計約 2,080 條 評測數據。
評測數據集
DoctorBench 的評測數據由 數百位國內頂尖醫學專家 參與構建與審核,確保高信噪比與臨床相關性。
| 評測類型 | 數據量 | 場景/任務數 | 評測維度數 |
|---|---|---|---|
| 大語言模型(LLM) | ~8,890 條 | 14 個場景 | 13 個維度 |
| 多模態大模型(VLM) | ~1,950 條 | 5 個任務 | 9 個維度 |
| 臨床任務(智能體) | ~2,080 條 | 6 個任務 | 6 類能力 |
| 合計 | ~12,920 條 | 25 個場景/任務 | — |
數據覆蓋臨床各科室,涵蓋內科、外科、婦產科、兒科、急診、皮膚、精神心理等各個學科方向。
快速開始
只需三步,即可提交您的模型參與 DoctorBench 評測:
第一步:註冊登錄 — 使用手機號註冊並登錄 DoctorBench 平台,填寫有效的聯繫郵箱。
第二步:配置模型 API — 在「我要評測」頁面,選擇評測類型,配置您的模型 API 信息(provider、base_url、api_key、model_name)。
第三步:提交評測 — 填寫模型元信息(展示名稱、參數量、開發者等),確認後提交。評測完成後可在「提交記錄」中查看結果。
API 接入配置
評測類型選擇
DoctorBench 支持三種評測類型:
| 類型 | 說明 | 預計評測時長 |
|---|---|---|
| 大語言模型(LLM) | 純文本對話能力評測 | 約 6-8 小時 |
| 多模態大模型(VLM) | 圖文聯合理解評測 | 約 3-5 小時 |
| 臨床任務(智能體) | 臨床任務執行、工具調用與多輪決策評測 | 約 2-3 小時 |
API 配置參數
| 參數 | 必填 | 說明 |
|---|---|---|
| Provider | 是 | API 服務提供商,選擇 custom 可接入任意 OpenAI 兼容接口 |
| Base URL | 是 | API 服務的基礎地址(如 https://api.openai.com/v1) |
| API Key | 是 | 您的 API 密鑰,僅在評測調用時使用 |
| Model Name | 是 | 模型標識符(如 gpt-4、qwen-max 等) |
目前支持 OpenAI 兼容接口。選擇
custom時,可自定義 base_url 接入任意兼容 OpenAI 格式的 API 服務。
連接測試
提交評測前,平台會自動對您的 API 配置進行連接測試,驗證:
- API 地址是否可達
- API Key 是否有效
- 模型是否能正常響應
如果連接測試失敗,請檢查以下常見原因:
- Base URL 格式是否正確(需包含完整路徑,如
/v1) - API Key 是否過期或額度不足
- 網絡是否可以訪問目標 API 地址
提交評測流程
完整的提交流程如下:
- 登錄平台 — 使用已註冊的手機號登錄
- 進入提交頁面 — 點擊頂部導航的「我要評測」或首頁的「提交模型評測」
- 選擇評測類型 — 從大語言模型、多模態大模型、臨床任務(智能體)中選擇
- 配置 API 信息 — 填寫 Provider、Base URL、API Key、Model Name
- 測試連接 — 系統自動驗證 API 可用性
- 填寫模型元信息 — 包括展示名稱、參數量(如 7B、70B)、開發者/組織名稱、發佈日期等
- 確認提交 — 檢查信息無誤後提交評測任務
- 查看狀態 — 在「提交記錄」中查看評測進度
評測完成後,您可以在提交記錄中查看評測狀態和結果。如果評測失敗,頁面會顯示具體的錯誤信息,您可以根據提示修正後重新提交。
常見失敗原因及處理
| 失敗類型 | 可能原因 | 處理建議 |
|---|---|---|
| 連接測試失敗 | API 地址不可達或 Key 無效 | 檢查 Base URL 和 API Key |
| 評測超時 | 模型響應過慢或網絡不穩定 | 確認模型服務正常運行後重試 |
| 配置錯誤 | 參數格式不正確 | 檢查 Model Name 拼寫、Base URL 格式 |
查看提交記錄
登錄後,您可以通過以下方式查看提交記錄:
- 點擊右上角頭像,在下拉菜單中選擇「提交記錄」
- 直接訪問
/submissions頁面
提交記錄頁面展示您所有的評測提交,包括:
- 評測狀態:排隊中、評測中、已完成、失敗
- 模型信息:模型名稱、評測類型
- 提交時間
- 評測結果(已完成的提交):點擊可查看詳細報告
評測榜單
DoctorBench 提供三個評測榜單,分別對應三種評測類型:
| 榜單 | 評測類型 | 主要排序指標 |
|---|---|---|
| 醫學大語言模型 | 大語言模型(LLM) | 綜合得分 |
| 醫學影像(多模態)榜單 | 多模態大模型(VLM) | 綜合得分 |
| 臨床任務(智能體)榜單 | 臨床任務(智能體) | 綜合得分 |
榜單規則
- 排序方式:按綜合得分(overall_score)降序排列
- 去重規則:同一模型僅保留 最近一次 提交的結果
- 公開條件:僅展示選擇公開評測結果的提交
- 數據來源:從已完成的提交中動態聚合,實時更新
展示信息
榜單中每條記錄展示以下信息:
- 排名(前三名顯示獎杯/獎牌圖標)
- 模型名稱
- 開發者/組織
- 參數量
- 綜合得分
- 各評測維度/任務類別得分(可按列排序)
評測報告解讀
每次評測完成後,系統會生成一份詳細的評測報告。不同評測類型的報告結構有所不同。
LLM 評測報告
LLM 報告按兩大受眾分組展示 14 個場景的評測結果:
- 面向普通用戶(7 個場景):症狀查詢、健康科普、用藥指導、報告解讀、慢病管理、資源導航、心理支持
- 面向醫療專業人士(7 個場景):臨床決策、醫學知識、科研輔助、文書生成、醫學教育、質量管理、倫理法律
每個場景包含:
- 綜合得分(average_total_score)
- 13 個評測維度的分項得分
- 缺失或未評估的維度顯示為 "N/A"
報告頂層還包含整體統計:模型名稱、平均總分、中位數總分、標準差。
多模態評測報告
多模態報告按 5 個任務類別展示:
- 模態識別與感知
- 跨模態關聯與推理
- 醫療記錄與報告生成
- 醫學知識問答
- 診斷與決策支持
每個類別包含平均得分。負分會以紅色標識提示。
臨床任務(智能體)評測報告
臨床任務(智能體)報告按 6 個任務類別展示:
- 智能分診與導診
- 多輪問診與病史採集
- 醫學工具調用與檢查安排
- 治療方案制定與執行
- 急診場景全流程處置
- 慢病管理與隨訪
每個類別包含平均得分。負分會以紅色標識提示。
得分計算方式
DoctorBench 採用 加權計分 方式計算綜合得分:
- 各維度設有不同的滿分上限,以反映其重要程度
- 核心維度(準確性、安全性)權重更高
- 綜合得分為各維度得分的加權匯總
特殊規則:
- 否決機制觸發時,準確性或安全性的嚴重問題將直接影響整體評級
- 零分仍顯示為 "0.00",不會被隱藏
- 缺失或無法評估的維度顯示為 "N/A",不參與加權計算
API Key 安全
DoctorBench 高度重視用戶 API Key 的安全性:
- 使用範圍:API Key 僅在評測調用過程中使用,用於訪問您的模型 API 進行評測
- 脫敏存儲:提交的配置快照中,密鑰字段經過脫敏處理,不以明文形式存儲
- 不回傳展示:任何 API 響應和頁面展示中均不包含明文 API Key
- 隔離評測:同類型的評測任務串行執行,避免配置相互覆蓋
建議您為 DoctorBench 評測創建專用的 API Key,並在評測完成後根據需要進行輪換。
數據隱私
- 評測數據:評測使用的數據集由 DoctorBench 團隊維護,不包含任何真實患者信息
- 模型響應:您的模型在評測過程中產生的響應數據僅用於評分計算
- 元信息:您填寫的模型元信息(名稱、參數量、開發者等)在選擇公開評測時會展示在榜單上
- 聯繫方式:註冊時提供的手機號和郵箱僅用於賬戶管理和必要的溝通
FAQ
評測需要多長時間?
評測耗時取決於評測類型和模型 API 響應速度。參考時長:大語言模型約 6-8 小時,多模態大模型約 3-5 小時,臨床任務(智能體)約 2-3 小時。您可在「提交記錄」中查看評測狀態。
支持哪些 API 提供商?
目前支持 OpenAI 兼容接口。選擇 custom 時,可自定義 base_url 接入任意兼容 OpenAI 格式的 API 服務。這意味著大多數主流大模型服務均可接入。
評測結果如何解讀?
評測結果包含各維度得分與綜合排名。完成評測後,您可以在「提交記錄」中查看詳細報告,包括各場景/任務的分項得分和維度分析。在「評測榜單」頁面可查看與其它模型的對比。
API Key 是否安全存儲?
是的。平台僅在評測調用時使用 API Key,存儲快照中的密鑰字段經過脫敏處理,不以明文回傳或展示。建議您創建專用的 API Key 用於評測。
支持多模態模型評測嗎?
支持。DoctorBench 提供完整的多模態大模型評測,涵蓋醫療影像、表格等模態的聯合理解與推理能力評估,包括模態識別、跨模態推理、報告生成、知識問答和診斷決策支持 5 個任務。
評測失敗了怎麼辦?
評測失敗時,「提交記錄」中會顯示具體的錯誤信息。常見原因包括 API 連接超時、Key 失效或模型響應異常。您可以根據錯誤提示修正配置後重新提交。
評測是否收費?
使用 DoctorBench 平台進行評測不收取費用。但評測過程中會調用您的模型 API,由此產生的 API 調用費用由您的 API 服務商收取。
評測數據來源是什麼?
DoctorBench 的評測數據由數百位國內頂尖醫學專家參與構建與審核,覆蓋臨床各科室。數據不包含真實患者信息,確保高信噪比與臨床相關性。
如何讓評測結果出現在榜單上?
提交評測時,可以選擇是否公開評測結果。選擇公開後,評測完成的結果將自動展示在對應的評測榜單上。同一模型僅保留最近一次提交的結果。
可以同時提交多個模型評測嗎?
可以提交多個評測任務。但為確保評測質量和資源分配,同類型的評測任務會串行執行。
如何聯繫技術支持?
提交評測時請填寫有效的聯繫郵箱。如有技術問題或需要溝通,我們會通過該郵箱與您聯繫。您也可以在提交記錄頁面查看評測狀態和詳細信息。